Twenty-five years after the Internet breakthrough, we’re facing–just as we speak–another ongoing dramatic change that opens up a whole new world of software opportunities. Like with the Internet, it’s about applications that just weren’t possible and conceivable before.
In laymen’s terms, LLMs (ie, GPT) are giving software applications the ability of understanding human language. The first effect of this is a dramatic simplification of user interfaces. Why going through a formal wizard when you can provide the same details to a chatbot and–differently from the recent past–have the bot to keep a much deeper track and full awareness of the scope and purpose of the conversation.
Add that OpenAI API extensions offer the possibility of shaping the visible data and possible answers from thet bot and you get a new form of programming–kind of conversational where you don’t code in C# but using prompts. Well, C# or classic programming is still needed to build the skeleton but presentation layer is getting a huge facelift. This article provides a glimpse of it.
LLM-based Applications
LLMs differ from other machine-learning models for their unique ability to capture long-range dependencies and rather intricate patterns in the processed data. the model takes input text and systematically predicts the next token in the sequence. Token-by-token prediction process is crucial for generating coherent and contextually relevant text. A token is usually a word, but it can any chunk of it, even a single character depending on the tokenization algorithm implemented by the LLM.
LLMs are guided in their guesswork by prompts. A prompt is a textual meta-instruction, conceptually analogous to the instructions of a programming language. The purpose of a prompt is instructing the LLM to perform certain specific searches without being re-trained. A LLM is trained on existing corpora of data and prompts are used to give context and restrict boundaries for a LLM to reply.
Put another wat, the LLM acts as virtual hardware while prompts act as virtual software. A prompt is mostly descriptive text, but it often needs to include context and sample data to work on and optionally even the structure of the desired output. Descriptiveness is crucial and coming up with the right prompt for a given task is, more often than not, a matter of trial-and-error.
To cut a long story short, LLMs enable us to write software applications that understand requests and return responses using the natural language (regardless of the spoken language).
Architecture of LLM-based Applications
Once the user’s query leaves the browser, it is subject to the action of a data filter tool to ensures that no unauthorized data makes it to the LLM engine. The core of an LLM application is the orchestration block, where the combined action of the prompt and orchestrators such as Langchain (or Microsoft’s Semantic Kernel) builds the actual business logic augmenting the data available using data pipelines like Databricks and Airflow and other tools like LlamaIndex and vector databases to deal with unstructured data.
The orchestrator may have the need to call into external, proprietary API and/or ad hoc data services. Note that in the passing of data around, the use of some cache is unavoidable. Finally, the output generated by the LLM engine can be further checked to ensure that unwanted data is not presented to the user interface (guardrails). The big picture is shown below.
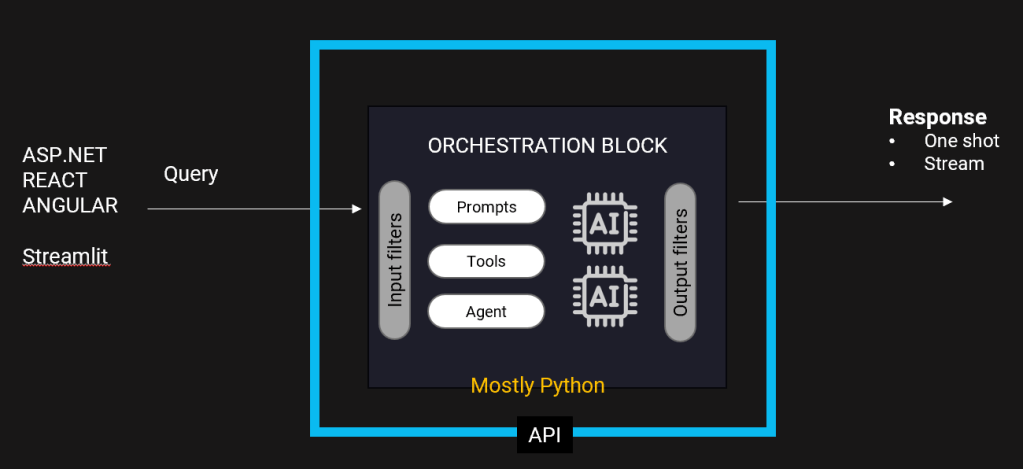
From the perspective of the frontend application (ASP.NET, React and the like), there are three main tasks to accomplish:
- Get the query from some input source (i.e., a textbox control, a file or whatever else)
- Arrange a call to some API
- Process the response whether it comes in a single step or is streamed
The orchestration block is deployed as an API and is mostly written in Python. The use of Python depends on the quality and flexibility of libraries acting as agents and the availability of dedicated tools and LLMs readymade for specific tasks. Langchain is the most popular of these frameworks. Semantic Kernel from Microsoft is conceptually equivalent to Langchain and allows to write C# and .NET code.
Conversational Programming By Example
Imagine you have an existing backend application that tracks daily tasks within your company offices, such as cleaning. Today, you may need someone to open a page and push a couple of buttons to signal start and finish. In a conversational paradigm, though, it can all happen using a Whatsapp chat.
The receipt of the message will trigger an underlying LLM app that ultimately ends up calling an new (or existing) process to finally update the database.

The LLM app processes the text and “understands” that it refers to the action of starting/finishing the cleaning task. Then it calls an existing API that identifies the right record to update on a given database.
Wait, it’s not black magic. A bit of code is still needed to ensure that the intent of the typed message is unambiguous and precise and data massaging may be needed to prepare the right call to the existing business logic. In some cases, new pieces of business logic may be needed too. Yet, it’s about using Whatsapp (or, why not, Teams) as an extension to the regular UI of applications.
This is possible now because only now we have a fully reliable technology to understand requests (better than NLP does) and return responses with more precise intents. The surrounding technologies (i.e., semantic engines like Langchain) also enables intents to be processed in a less schematic but still rigorous pipeline. No more decision trees under the hood of chatbots, but agents and tools orchestrated to a given task.
Nothing special; just the natural evolution of technology.
